Making Sense of Cannabis Strains Through Chemometrics in Review
The cannabis industry is constrained by the continued use of acronyms and nonstandard abbreviations for strain naming in lieu of a scientific-based standardized classification convention or lexicon. Applying chemometric tools can result in not only the authentication of a given cannabis cultivar but also provide a quality control mechanism for both cannabis flower and any resulting cannabis-based drugs.


Photo © AdobeStock.com/Ayehab



Figure 1: Map of the geographical distribution of the cannabis gene pools. Boxed labels indicate area of origin from which the cannabis plant spread alongside humanity. North American drug-type varieties (MJ) are likely stabilized poly-hybrids of BLD (C. sativa afghanica) and NLD (C. sativa indica).



Figure 2: Terpenoid chemovar clusters.
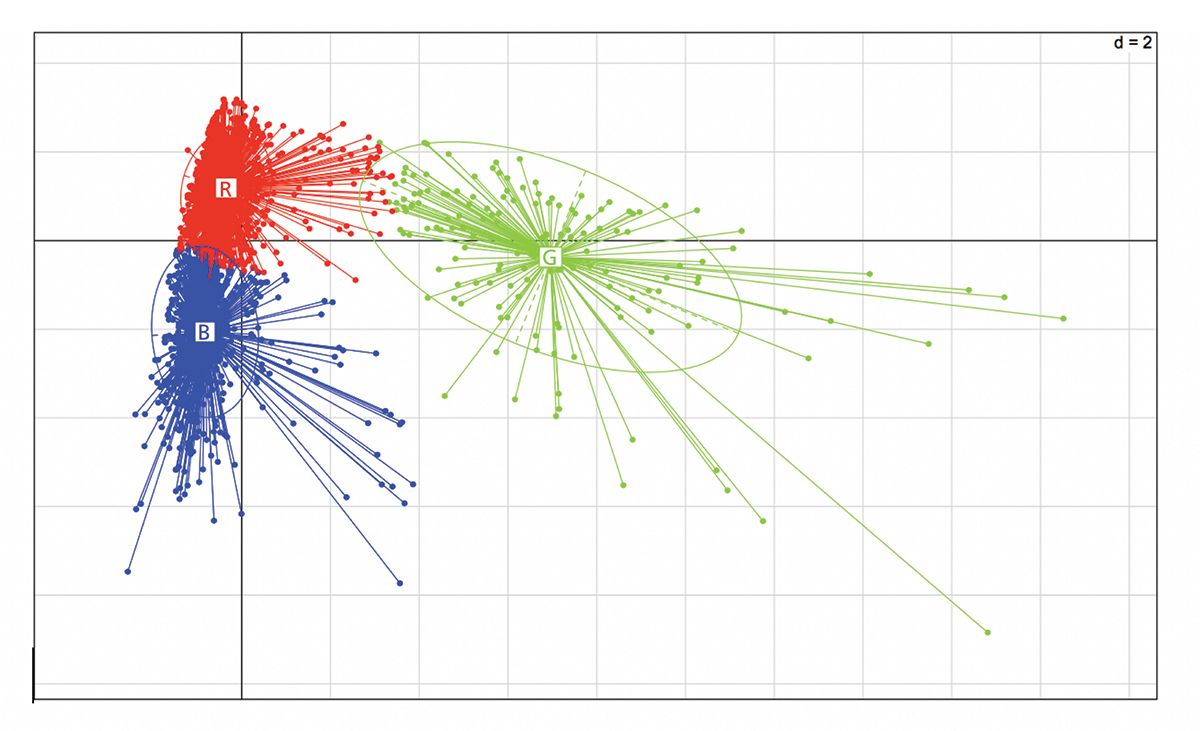


Figure 3: Cannabinoid and terpenoid clustering.



Figure 4: Principal component analyses based on 21 SNPs identified using the chemometric model based approach described above. The 70 accessions shown were genotyped using Medicinal Genomics’ Strainseek V2 assay at about 10,000 SNPs, loading extraction was used to isolate SNPs associated with the most parsimonious chemovar classification model based on terpene expression, with three major groups including myrcene (red), limonene (blue), and terpinolene (green) dominant accessions.
The over-proliferation of cannabis strain names following the establishment of cannabis complicit-states in the U.S. has led to confusion and resulted in a lack of transparency for the consumer at the dispensary. There are many contributing factors as to why we find ourselves in this current state of disorganization, but primarily it is a consequence of the covert nature of the industry for the past 70 years where amateur plant breeders have been busy at work creating undocumented hybrid strain heritage resulting in a largely indefensible distinction between indica and sativa even though the vast majority of cannabis sold in dispensaries still hold on to this insupportable demarcation.
Beyond the vernacular conventions, the genus Cannabis harbors immense genetic diversity that is thought to segregate into four main gene pools (Figure 1): Narrow Leaf (European) Hemp (NLH; C. sativa sativa), Broad Leaf (Chinese) Hemp (BLH; C. sativa chinensis), Narrow Leaf Drug-type (NLD; C. sativa indica), and Broad Leaf Drug-type (BLD; C. sativa afghanica). Support for this proposed clustering into sub-species has recently gained support from investigations using genetic markers suitable for within species comparison, such as single nucleotide polymorphisms (SNPs) (1–4) and microsatellites or simple sequence repeats (SSRs) (5). Such endeavours have yielded some congruent patterns, but in a general sense, all authors agree on the fact that cannabis strains found in the current medical and recreational markets in North America (referred to hereon as MJ strains) are extensive hybridized plants (four-way poly-hybrids) with NLD and BLD ancestry and with high cannabidiol (CBD) varieties incorporating some portion of the pool of the European or Chinese hemp or novel mutants in cannabinoid synthesis pathways.
Further complications caused by the black-market of cannabis breeding over the past century has caused much speculation as to the origins of particular traits (such as the origin of minor cannabinoids, for example, cannabichromene [CBC], tetrahydrocannabivarin [THCV], and cannabidivarin [CBDV]). Of particular note, accessions of divergent origins may display similar traits as a result of intense selective pressures imposed by cultivators. One such example is the fact that modern drug-type cannabis has accumulated multiple copies of the tetrahydrocannabinolic acid synthase (THCAS) gene, thus potentially responsible for the increasing expression of THC in commercial cannabis accessions compared to heirloom varieties (6).
North American cannabis strain naming is in need of adoption of a structured classification scheme based on horticultural and agronomic standards. The cannabis industry is being constrained by the lack of a scientific-based standardized classification convention and the continued use of acronyms and nonstandard abbreviations. The ramifications include a lack of quality control of product, a hit and miss process based on the sophistication of the entity and specific state regulations, and enforcement of those regulations. Therefore, the cannabis consumer patient often times has no real idea of the composition, consistency, or comparability of the cannabis product that they purchase. In today’s sophisticated world, the persistence of the current vernacular nomenclature combined with classifying cannabis chemovars as sativa or indica is scientifically indefensible based on peer-reviewed findings (1).
In these scientific times, exceptional investigative data analytic tools are available to bring definition to cannabis strains and clear the way to provide meaningful enlightenment including the basis for intellectual property. The rapidly expanding acceptance of legal cannabis in the U.S. on a state-by-state basis and the current Canadian-wide legal pot industry has seen new serious scientific attention drawn to address this flagrant deception at the consumer level. Data analytic tools include high resolution mass spectrometry to determine the chemical profile of cannabis strains, principle component analysis (PCA) to analyze the data (7,8), and genotyping to identify unique SNPs associated with the particular chemical profile of a given cannabis cultivar and coming soon, sensory profiling (9).
The opportunity now exists to connect the human experience of sensory perception via our olfactory receptors with the quantifiable chemical phenotype of individual cannabis cultivars from analytical chemical analysis and as verified through genotyping and to one day arrive at an identifiable physiological endpoint. As Mendocino County, California seeks to establish cannabis appellations based on soil and microclimate in the same vein of viniculture (10), it is imperative today to apply validated scientific principles to assign a standard lexicon with concise descriptors. It will no longer be enough to apply only one descriptor to identify a cannabis cultivar; chemical analysis combined with genotyping and human smell will complete the denomination and eliminate misconceptions and worse, consumer fraud.
The rapidly expanding world cannabis market, which is growing at a much faster pace than the state-by-state adoption in the U.S., should be motivation for cannabis cultivators to adopt a uniform cannabis classification. As U.S. states are starting up cannabis programs one-by-one with little cooperation or standardization, entire countries are doing so with economic efficiency at the same pace. Globally, about 2.25% of the population consumes cannabis. Both medical and recreational cannabis make up a multibillion-dollar global industry. Lawful medical cannabis programs have already been implemented in Canada, Mexico, the United Kingdom, the Netherlands, Australia, Germany, Italy, Israel, Poland, the Czech Republic, Spain, Greece, Colombia, Uruguay, Peru, South Africa, and many other countries in quick pursuit regardless of global drug policy, which the World Health Organization is poised to re-evaluate in 2018.
Why Do We Need This?
The main barrier to the adoption of a new cannabis nomenclature will be changing human behavior, given that cannabis variants have been introduced, named, and hybridized at will until now. The motivating event for adoption of a new nomenclature will occur in Canada and California, where legal, regulated cannabis came online in 2018. California will be the largest cannabis recreational market in the biggest agricultural economy in the United States, and Canada is already a global cannabis exporter. Cannabis cultivation will rapidly mature and a cannabis registry will be one important part of that process as the industry rapidly evolves toward big agriculture versus boutique cannabis growers; in both instances, cannabis cultivar authentication will be key to success, and an important means of keeping market share.
An added value of having authenticated raw cannabis material is to help progress our understanding of the medical benefits of a particular cannabis chemotype, with the ultimate goal of correlating chemotypes with specific pharmacological outcomes. Ultimately it will not be the cultivar name that will be sought out, but the chemoprofile it produces, and the sensory perception that it elicits, at which point cultivars sharing the same chemoprofile could be combined prior to extraction and formulation.
The Approach and Challenge
Regulators should institute broader chemical profiling, genotyping, and mandatory cannabis cultivar registration with specific criteria required prior to ever growing the cultivar. Currently, only Nevada and Massachusetts require terpenoid analysis on every cannabis sample. Further confounding the situation for the recreational cannabis consumer and medical marijuana patient is the sole reliance placed on tetrahydrocannabinol (THC) content to establish the inherent value of flower, rather than taking the entirety of the pharmacologically active chemoprofile of the plant into account. Both state regulators and cannabis testing laboratories can help relieve the growing uncertainty. And those cannabis testing laboratories that go beyond simply quantifying cannabinoid potency and quality assurance are in a unique position to demystify cannabis strains through expanded chemometrics, genotyping, and consumer education. Both approaches are aimed to give cannabis consumers more confidence in what they are purchasing. On the upside, findings indicate that cannabis consumers are willing to pay a premium for genotyped, authenticated flower.
Although considerable chemoprofiling data have been gathered by various cannabis laboratories and groups, because of the lack of standardization in analytical methods used to collect chemoprofile data, one can never be fully confident with cross analyses. Likewise, because of nonstandardized sequencing approaches in genotyping, not all genetic sequence data are comparable. Standardization of analytical methodologies is urgent.
What is Chemometrics?
Chemometrics is the use of statistical and mathematical methods to improve our understanding of chemical data (11). For the statistical analysis of chemical data, one often looks at multiple variable inputs (chemical components) and their interaction. Classic model assumptions are often not fulfilled by chemical data, for instance there will be less observations than variables, or correlations between the variables occur. For this purpose, multivariate data analysis, which is the simultaneous observation of more than one characteristic for a set of data, is particularly interesting and well suited for exploratory analyses to interpret patterns in the data and develop models. These models can then be routinely applied to future data to predict the same parameters of interest whether it is to discriminate the analysis of edible oils and fats by fourier transform-infrared (FT-IR) spectroscopy (12) or to detect the adulteration of virgin olive oil using mid-IR spectral chemometric data (13), the models are applicable to data obtained from any of a number of analytical instruments.
Classical Applications of Chemometrics
Principal component analyses (PCA) is one of the most common and simplest means to reduce information from multiple variables (for example, cannabinoid and terpenoid profiles) into synthetic variables (principal components) that summarize and encompass the variation and explains a certain percentage of the observed patterns. Cluster analysis (CA) provides another classic means to separate samples into groups that share a common property. These popular methods have been applied to clinical data for disease diagnostic (14), as an efficient and powerful tool for quality control and authentication of different herbs (15), the identification of the origin of consumer goods (16), and the classification of cannabis cultivars into chemovars (17). To take it one step further, one could model the observed clustering or structure based on chemical profiles to derive stable methods of naming taxonomic or pharmacological groups.
Chemometrics has been applied for the past two decades for many diverse purposes including the classification of river water samples in Poland for pollution monitoring (18), to identifying adulterants in freeze dried coffee (19), and to identify the authenticity of food based on quality attributes (20). The application of chemometrics to cannabis has been a natural extension. Because chemical constituents can vary for any crop group depending on growing environment, harvest time, and subsequent drying and curing conditions, it seems reasonable to apply any of a number of analytical techniques available. Those techniques include high performance liquid chromatography (HPLC) coupled to mass spectrometry (MS) and gas chromatography (GC) coupled to MS, which can be used to establish the profile of cannabis-based chemicals through chemotyping to assure the repeatability and quality of pharmacologically active compounds in a given formulation. The concept of equivalence in herbal formulations was started in Germany (21) to establish clinically proven reference material.
Chemometrics Applied to Cannabis Breeding
Classical approaches to breeding are based on the selection of particular traits of interest in a large set of germplasm. The objectivity of the selection pressure exerted by plant breeders will depend on the techniques available to decipher cryptic traits. Chemical expression is temporarily cryptic for volatile compounds, such as terpenoids, and permanently cryptic in the case of cannabinoids that do not have perceivable odors. As such, the ability to detect particular molecules at early stages has the potential to speed up breeding efforts and reduce financial burden of extensive breeding experiments.
A prime example of a targeted breeding effort in cannabis was undertaken by Napro Research (22). Starting from a foundational breeding program developed by Ryan Lee, and using only conventional breeding techniques, the team selected from thousands of individuals plants and from a large set of varieties to develop high terpenoid and resin producing lines. These plants were initially screened for cannabinoids and terpenoids, and about 20 varieties of interest were thus selected for particular breeding goals, including rare traits and high, or interesting essential oil production. Using scaled metrics, the authors prioritized breeding pairs and followed the offspring through several generations to stabilize the traits of interest. They were the first to demonstrate the ability to produce cannabis accessions with divergent cannabinoids chemotypes with type I, II, and III plants expressing identical terpenoid profiles. The ability to modulate cannabinoid ratios while maintaining stable essential oil production offers many promises for both the medical and recreational markets. This information was further refined into color coded archetypes based on the full chemical profile of each variety and can be found online (47).
Application of Chemometrics to Cannabis Everyday
Besides the hopes to accelerate targeted breeding programs, insight into the chemical expression of individual cannabis varieties offers great promise to reach a consensus in terms of product nomenclature. Categorizing and naming biodiversity is an artificial agreement humanity has decided upon, using objective metrics such as chemical profiles that provide a repeatable means to classify organisms below the species level.
As large state- or nation-wide datasets containing chemical information of cannabis varieties from a large number of cultivators emerge, so does our capacity to synthesize this information into statistically supported groups. At the consumer level, this will translate into a meaningful system relying on multiple lines of evidence such as genetic lineage and chemical expression of terpenoids with given pharmacological properties that will help guide the end user and the medical professional towards an enhanced understanding of the cause-effect relationship between chemical profile and intended pharmacological effects.
Basis for Proprietariness
Assigning a chemoprofile and associated genotype to a cannabis cultivar would enhance the value of that cultivar and enable the ability with genotyping to acquire proprietary status through cultivar registration, trademarking, and patenting. In that vein, a number of utility patent applications have been filed with regards to specialty cannabis, their chemical profile, and processes used to generate them (23–25). Other plant patent applications have also been filed for hybrid (26–28) and heirloom (29) varieties, making claims for particular cannabinoid or terpenoid expression profiles, such as the variety Avidekel with a high amount of CBD (16.3%) and a very low amount of THC (0.8%).
Besides making for more defensible intellectual property (IP), having a chemical and genetic fingerprint of a cultivar would allow for authentication of the product at any time in the future and cultivar registration would prevent the reuse of the same cultivar name. Standardized analytical methods and data analytics are required to routinely characterize the large range of biologically active secondary metabolites made by the cannabis plant. Because the chemical profile can be influenced by the growing conditions and environment, it is important to also trace unique genetic markers associated with the desired chemotype. The associated genetic markers can be acquired from genotyping data and are required for the future breeding of cultivars specific for pharmacological use, fiber, food, or fuel.
Terpenoids as Distinguishing Analytes
Since the vast majority of cannabis being grown in the U.S. is drug-type I defined as having a cannabidiolic acid (CBDA)–tetrahydrocannabinolic acid (THCA) ratio of <0.5%, various efforts have been underway to make sense of cannabis strain names through the use of data analytics on broader cannabis flower chemoprofiles. It turns out that cannabis terpenoids not only imbue pharmacologically important attributes, but uniquely provide a basis for a secondary nomenclature after established cannabinoid content. We, and others, have shown that while unique terpenoid chemoprofile patterns exist and can be assigned to a cannabis cultivar, the absolute amounts of any given terpenoid can be influenced by genetic, epigenetics, environmental, and cultivation factors (30–33).
Terpenes, or more accurately terpenoids, contribute the aromatic properties of cannabis and essential oils from many other plant species. The particular terpenoids associated with any given plant species turns out to be fairly specific; for example, limonene in lemons, beta-myrcene in mangoes, and so on. In cannabis, there is a range of potential terpenoids based on the genetics and expression profiles of a given cannabis cultivar. Terpenoids can also modulate the medicinal or recreational attributes of a given cannabis cultivar.
State-mandated cannabis testing regulations have resulted in a large database from the analysis of thousands of individual cannabis flower samples from artificially restricted geographical regions including terpenoids. The resulting detailed chemical database can serve as the basis for the development of a chemotaxonomic classification scheme outside of conjectural cultivar naming by strain. Of the roughly 140 identified terpenoids in cannabis, there seems to be consensus in the literature that between 17 to 19 are the most useful in defining a cannabis chemotype (34–36) and perhaps as few as three (33,37). Terpenoid content in the cured flower can range from 0.5% to 3% (36).
The obsession surrounding cannabinoids, in particular THC and CBD content fueled by growers and consumers alike, has overshadowed the importance of the terpenoid profile and content in specific cannabis cultivars. Today we know that terpenoids can be used to distinguish cannabis cultivars (17,33,37–40). Terpenoids demonstrate effects on the brain at very low ambient air levels in animal studies (41) and it is conjectured that terpenoids contained in cannabis also contribute to pharmacological activity as part of the entourage effect.
Broader chemotaxonomic classification schemes for cannabis cultivars have been reported based largely on cannabis strains grown in restricted geographic regions, such as in California under an unregulated testing environment (36) or in the Netherlands from strains grown by a single grower or collected from multiple commercial sources (17). In the only large-scale study, 2237 individual cannabis flower samples, representing 204 individual strains across 27 cultivators in a tightly regulated Nevada cannabis testing market, were analyzed across 11 cannabinoids and 19 terpenoids (32). Even though 98.3% of the samples were from drug type I cannabis strains by CBDA–THCA ratio of <0.5%, PCA of the combined terpenoid and cannabinoid dataset resulted in three distinct clusters that were distinguishable by terpene profiles alone, suggesting that just three terpenoid cluster assignments account for the diversity of drug-type cannabis strains currently being grown in Nevada (Figure 1). The inclusion of cannabinoid chemoprofile data did not add any further resolution beyond the three terpenoid clusters (Figure 2).
Terpenoid Clustering
In a previously published large-scale Nevada PCA study (33), the combined dataset resulted in three clusters distinguishable by terpene profiles alone (Figure 2) where cannabinoid content was of no distinguishing value (see Figure 3). Just three to five terpenoids—beta-myrcene, beta-caryophyllene, limonene, terpinolene, and gamma terpinene—were able to discriminate, which strongly suggests that a further delineation could be made based on the mandatory analysis of just three to five terpenoids by all independent cannabis testing laboratories (33). Importantly, when focusing on individual cultivars by name, such as Gorilla Glue #4 or Golden Goat, across studies, similar trends in chemoprofiles persist. Here we propose a further delineation of drug type I into the three subtypes based on limited terpene chemoprofiling:
- Type IA: beta-myrcene, α-pinene, limonene, beta-caryophyllene
- Type IB: gamma-terpenine, terpinolene, ocimene
- Type IC: limonene, beta-myrcene, beta-caryophyllene, α-pinene (BLDT)
Others have shown that replicately-grown batches of the same cannabis cultivar produce remarkably consistent chemoprofiles (36) and that the three distinct genetic groups of broad leaflet drug type (BLDT), narrow leaflet drug type (NLDT), and hemp also show distinct terpenoid profiles overall (3). In the Nevada study, in an artificially restricted geographic region, individual cannabis cultivars remain remarkably consistent for terpenoid profiles, even across different cultivators, and cluster into one of the three groups.
It is interesting that for the past 70 plus years of covert cannabis breeding, primarily selecting for high THC content, the diversity and prevalence of terpenoids has seemingly been maintained. Now that the terpene synthase genes and transcriptome have been described for Cannabis sativa L., focused marker-assisted breeding programs will be able to modulate terpenoid content and create cultivars with standardized terpenoid profiles with the ratio of CBDA–THCA desired (42) and start to finally address the long taxonomically-neglected cannabis plant (43).
Future cannabis data analytic studies should take care to start with established stable genetic fingerprints of all cultivars included with precise note-taking on growth conditions to help understand any inherent future variability in terpenoid analytical testing data.
There is currently no adopted cannabis classification system based on terpenoid profiles, even though several scientists have promoted the idea. Furthermore, we now have numerous robust datasets that clearly reveal clustering power within a handful of terpenoids while the existing vernacular classification system, largely based on the phenotype of the strain, continues to be heavily promoted by several commercial entities spreading confusion today.
We Only Know What We Know
We can look to established agricultural commodity industries as models to see how new research findings—such as elucidating terpene pathways in the case of cannabis or introduction of pest-resistance in the case of wheat—can easily be incorporated, lead to registration of a new cultivar, and only strengthen the intellectual property position of specific cultivars. Even though we do not have a complete assemblage of the genes involved in what we believe are the pertinent pathways that contribute to the pharmacological activities of cannabis, nor do we have a complete picture of the human genetic variants that contribute to a therapeutic outcome, we have a starting point with terpenoids. Marketing and branding will require a more reliable experience or therapeutic outcome, and, therefore, tighter controls on authenticating what is actually being grown and processed.
Targeted SNP Assays to Mix and Match
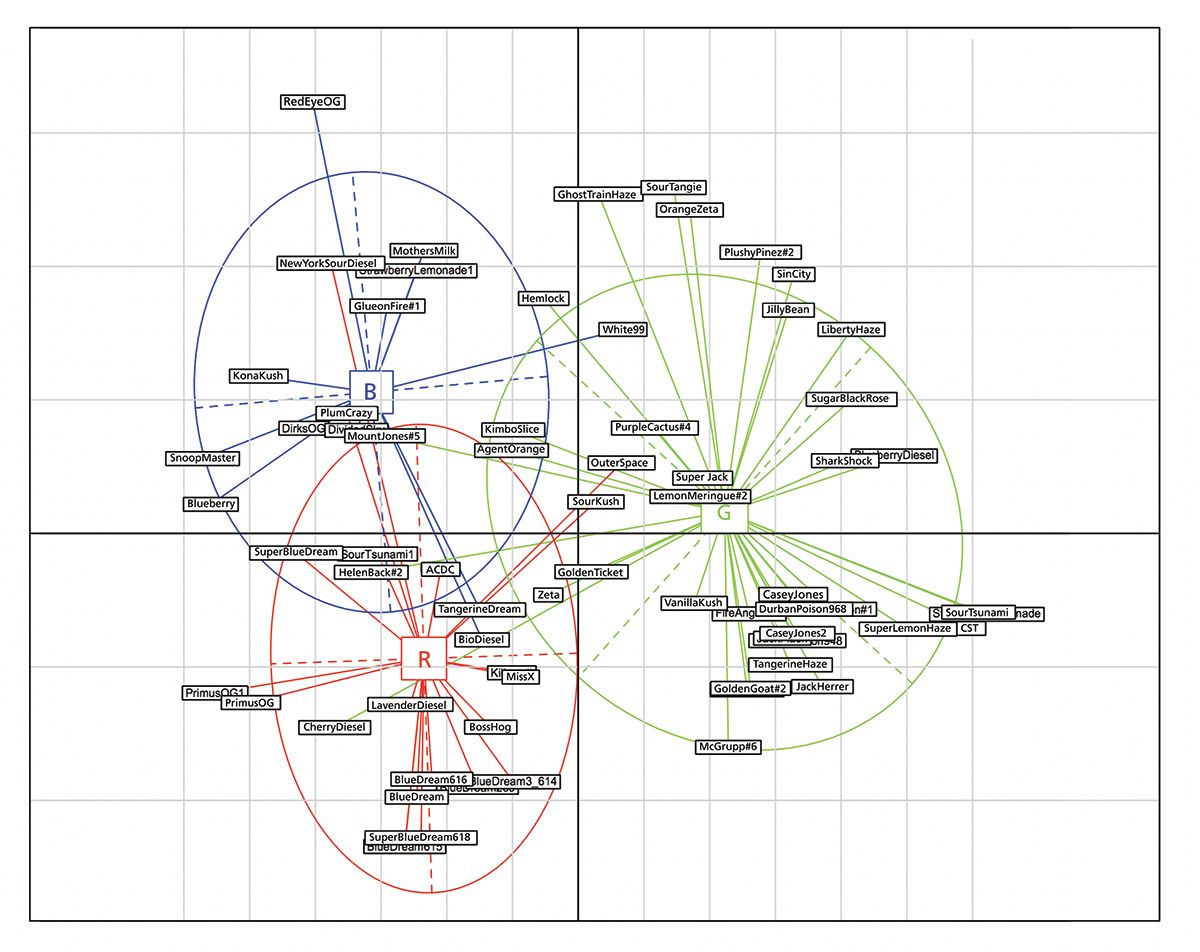
Using chemometrics on cannabinoid and terpenoid expression data to segregate accessions into clusters provides the initial model on which to base targeted sequencing based on cosegregation of genetic markers associated with key traits of interest. Correlating the expression of diagnostic terpenes with variation at genetic loci thus offers the opportunity to identify informative mutations or SNPs in the cannabis genome that are associated with, for example, terpenoid expression (Figure 4) (4,44). These genetic markers can be assayed in a time and cost-effective manner using several variations of the polymerase chain reaction (PCR), as well as microfluidic approaches to enable high throughput genotyping.
A recent example includes 21 informative SNPs associated with terpene expression in cannabis samples from Nevada (Figure 4). The data comes from more than 2000 samples from 115 strains and 37 cultivators typed at 19 terpenoid and 11 cannabinoids markers (33). The chemotypic data, coupled with genome-wide genetic data from 70 accessions was used to constrain the structure of the dataset for use with the overfitting discriminant analysis of principal components (DAPC) algorithm described by Henry (2). One can note that the information contained in the 21 selected SNPs provide a broad means to classify accession into their respective groups based on their dominant terpene expression. Seven accessions in total appear to be misclassified into their inferred terpene group, five of which (Cherry Diesel, Helen Back #2, Sour Kush, Outer Space, and New York Sour Diesel) are predicted to express terpenes not typically seen based on the chemotypic data alone. This discrepancy may also be the result of varying environmental factors during cultivation, since the data used was from plants grown in different cultivation locations and not under a common-garden.
One particular advantage of using the genetic tools as a proxy for the above mentioned chemometric approach is that relatively simple equipment can be utilized to type these molecular markers and essentially make it a method of choice for rapid and cost-effective field and laboratory determination of cannabis origin and key agronomical and pharmacological traits. Quantitative PCR (qPCR) is considered the gold standard for accurate, sensitive, and fast quantification of nucleic acid sequences and has been established and validated for a broad range of applications including genotyping, pathogen detection, DNA methylation analysis, and other applications. Laboratory equipment is currently available under $6000 for a dual channel system (48).
Upside for Cannabis Science
Most of the cannabis-complicit countries regulate cannabis as a medicine. Israel in particular is at least a decade ahead of the U.S. in instituting standardization in the cultivation, extraction, and formulation of cannabis for clinical trials, leading to patentable drugs that will eventually find their way to the U.S. Food and Drug Administration (FDA) for approval and entry into the lucrative prescription drug market in the U.S. Now the U.S. has its neighbor, Canada, not only following in the footsteps of Israel but also legalizing adult use cannabis at the Federal level. U.S. cannabis companies need to play catch up to gain market share, starting with distinguishing cannabis cultivars from the staggering number of named cannabis strains being grown.
Steps Toward Standardization
Cannabis strain authentication entails both establishing a strain’s chemoprofile, the chemical composition including cannabinoids and terpenes, if not more, as well as the genotype of the strain, resulting in a fingerprinted signature. Cannabis testing laboratories are the path to strain authentication. Strain authentication is an important step toward development of reliable, consistent whole plant-based medical marijuana and patient consumer confidence, bringing legitimacy to the cannabis industry.
The first step toward standardization in cannabis strain naming would be to throw out the current unregulated model and replace it with the horticultural and agronomic convention of cultivar names. For example, the strain Blue Dream would become Cannabis sativa cv. Blue Dream. The second step would be to associate a referenced chemotype and genotype with Cannabis sativa cv. Blue Dream. The combination of the Blue Dream cultivar name with its chemotype and referenced genotype would authenticate it.
All stakeholders need to participate, from growers to state departments of agriculture to scientists actively working in this area. State regulatory agencies will need to be active participants in creating and overseeing a cannabis registration. There are hopeful signs from the Association of Official Seed Certifying Agencies (AOSCA) with their interest in forming a varietal hemp working group in 2018. In Canada, a plant breeders’ rights certificate was granted to a federally licenced producer for a type I cannabis plant for their variety “MR2017002” (45), adding to the already existing repository for type II hemp varieties currently registered in the country.
As the cannabis industry continues to grow across the U.S. at a rapid pace, the competition amongst growers and producers is also heating up. This competition is reflected in dropping prices at both the wholesale and retail level. There are few options for growers to regain market share in the flooded retail market space. Growers can either cut their costs by engaging testing facilities that provide fewer services and questionable testing results, or they can choose the high road and distinguish their harvests from their competition through authentication of their strains. Authenticated cannabis products command higher prices at both the wholesale and retail level, and the requirement for strain confirmation is an inevitable regulatory requirement.
Resulting Utility
Applying chemometric tools to the authentication and quality control of both cannabis flower and cannabis-based drugs can be both efficient and powerful. The efficiency comes from the ability of any cannabis testing laboratory or state reference laboratory to apply standardized analytical methods to obtain phytochemical and genotypic data profiles using more than one analytical method. With the hopeful advent of mandatory cannabis cultivar authentication, cannabis science can advance more readily.
Creating a new lexicon for cannabis cultivars based on scientifically quantifiable values would help to advance cannabis research and commercial cultivation benefiting both regulators and consumers. A new simplified vocabulary that links the chemical makeup of a cannabis cultivar with its olfactory perception could be added to the METRC barcode so that consumers and state regulators know exactly what is being claimed by the cultivator. And verification by specific genotyping would provide the trifecta for cultivar registration. The latter would prove particularly interesting to implement through blockchain technologies for integration into seed to sale tracking programs (46).
Not to be ignored is the sensory perception of the chemical composition of a particular cannabis cultivar and the subconscious or conscious olfactory judgment that is made by the individual cannabis user. We’re just starting to understand how aroma influences one’s discrimination of cannabis and the application of statistical techniques to describe that olfactory experience (9). Future studies linking olfactory perception with chemical profiling, in particular terpenoid profiling, will demonstrate the level of perception already inherent in humans. The vast unknown is what physiological cascade of events that odorant sensation begets.
Empowering the Cannabis Industry, Cultivator, Regulator, and Consumer
As the industry rapidly evolves toward big agriculture versus boutique cannabis growers, cannabis cultivar authentication will be a key to success and keeping market share in North America. The cannabis industry must continue its evolution towards an evidence-based model of medicine where cannabis chemical and genotypic profiles need to be correlated with their pharmacological activities using metabolic profiling with multivariate analysis requiring a reoccurring authentication, that is, a certification requirement for cultivators to be in the game.
The current self-inflicted confusion within the U.S. and Canadian cannabis industry is an opportunity to demonstrate scientific ingenuity against the rapidly maturing global cannabis industry, where outdoor growing costs are a fraction of the indoor energy intensive grows. Throwing out unnecessary impediments should be a priority, starting with nonstandard strain naming in favor of the agronomic and horticultural practice of registered “cultivar” names based on full genome sequencing, broad chemometrics, and genotyping to allow for consistent, reproducibly-effective comparisons across the cannabis industry. This will enable trademarking or patenting of specific cultivars.
References:
- J. Sawler, J.M. Stout, K.M. Gardner, D. Hudson, J. Vidmar, and L. Butler, et al., PLoS One 10, e0133292. http://dx.doi.org/10.1371/journal.pone.0133292 (2015).
- P. Henry, PeerJ PrePrints 3, e1980, doi: 10.7287/peerj.preprints.1553v2 (2015).
- R. Lynch, D. Vergara, S. Tittes, K. White, C.J. Schwartz, M.J. Gibbs, T.C. Ruthenburg, K. deCesare, D.P. Land, and N.C. Kane, Crit. Rev. Plant Sci. 35, 349–363, http://dx.doi.org/10.1080/07352689.2016.1265363 (2015).
- P. Henry, PeerJ PrePrints 5, e3307v1, https://doi.org/10.7287/peerj.preprints.3307v1 (2017).
- C. Dufresnes, C. Jan, F. Bienert, J. Goudet, and L. Fumagalli, PLoS ONE 12(1), e0170522, https://doi.org/10.1371/journal.pone (2017).
- K. McKernan, Y. Helbert, V. Tadigotla, S. McLaughlin, J. Spangler, L. Zhang, and D. Smith, bioRxiv doi: https://doi.org/10.1101/028654 (2015).
- L. Ericksson, T. Byrne, E. Johansson, J. Trygg, and C. Vikström, Multi- and Megavariate Data Analysis Part 1: Basic Principles and Applications, Second Ed. (Umetrics, Umea, Sweden, 2006).
- L. Eriksson, E. Johansson, N. Kettaneh-Wold, J. Tyrgg, C. Wikström, and S. Wold, Multi- and Megavariate Data Analysis Part 1: Basic Principles and Applications, Second Ed. (Umetrics, Umeå, Sweden, 2006).
- A. Gilbert and J.A. DiVerdi, PLoS One 13(2), e0192247, https://doi.org/10.1371/journal.pone.0192247 (2018).
- D. Sweeney, “Mendocino County divided into cannabis appellations,” North Bay Business Journal (2016).
- M. Otto, Chemometrics. Statistics and Computer Application in Analytical Chemistry, (Wiley-VCH, New York, 1998).
- Y. Hong, et al., Food Chem. 93, 25–32 (2004).
- G. Gurdeniz and B. Ozen, Food Chem. 116, 519–525 (2009).
- N.A. Dang, H.G. Janssen, and A.H. Kolk, Bioanalysis 5(24), 3079–3097 (2013).
- H.A. Gad, S.H. El-Ahmady, M.I. Abou-Shoer, and M.M. Al-Asisi, Phytochemical Analysis 24(1), 1–24, https://doi.org/10.1002/pca.2378 (2012)
- I. Geana, A. Iordache, R. Ionete, A. Marinescu, A. Ranca, and M. Culea, Food Chem. 13, 1125–113 (2013).
- A. Hazekamp, K. Tejkalova, and S. Papadimitriou, Cannabis and Cannabinoid Research DOI: 10.1089/can.2016.0017 (2016).
- T. Kowalkowski, R. Zbytniewski, J. Szpejna, and B. Buszewski, Water Research 40, 744–752 (2006).
- R. Briandet, E.K. Kemsley, and R.H. Wilson, J. Science of Food and Agriculture 71, 359–366 (1996).
- L.M. Reid, C.P. O’Donnell, and G. Downey, Trends Food Sci. Technol. 17, 344–353 (2006).
- V.E. Tyler, J. Nat. Prod. 62, 1589–15792 (1999).
- M.A. Lewis, E.B. Russo, and K.M. Smith, Planta Med. 84, 225–233 (2018).
- E. De Meijer, “Cannabis sativa plants rich in cannabichromene and its acid, extracts thereof and methods of obtaining extracts therefrom.” Google Patents, https://www.google.com/patents/US20110098348 (2011).
- M.A. Lewis, M.D. Backes, and M. Giese, “Breeding, production, processing and use of specialty cannabis.” Google Patents, https://www.google.com/patents/US9642317 (2015).
- M.W. Giese MW and M.A. Lewis, “Systems, apparatuses, and methods for classification.” Google Patents, https://encrypted.google.com/patents/WO2016123160A1?cl=en (2016).
- Y. Cohen, “Cannabis plant named ‘avidekel’.” Google Patents, https://www.google.com/patents/US20140259228 (2014).
- Y. Cohen, “Cannabis plant named erez.” Google Patents, https://www.google.com/patents/US20140245494 (2014).
- Y. Cohen, “Cannabis plant named midnight.” Google Patents, https://www.google.com/patents/US20140245495 (2014).
- S.W. Kubby, “Cannabis plant named ‘Ecuadorian Sativa’.” Google Patents, https://www.google.com/patents/USPP27475 (2016).
- O. Aizpurua-Olaizola, U. Soydaner, E. Öztürk, D. Schibano, Y. Simsir, P. Navarro, N. Etxebarria, and A. Usobiaga, J. Natural Products 79, 324–331 (2016).
- M. Sexton and J. Ziskind, “Sampling cannabis for analytical purposes.” http://liq.wa.gov/publications/Marijuana/BOTEC%20reports/1e-Sampling-Lots-Final.pdf (2013).
- D.J. Potter, Drug Testing Anal. 58, S54–S61, http:// dx.doi.org/10.1002/dta15 (2013).
- C. Orser, S. Johnson, M. Speck, A. Hilyard, and I. Afia, Natl. Prod. Chem. Res. DOI: 10.4172/2329-6838.1000304 (2017).
- Hillig KW (2004) A chemotaxonomic analysis of terpenoid variation in Cannabis. Biochem. Syst. Ecol. 32, 875–891. http://dx.doi.org/10.1016/j.bse.2004.04.004
- Hazekamp A, Fischedick JT (2012) Cannabis – from cultivar to chemovar. Drug Test Anal 4:660–667. http://dx.doi.org/10.1002/dta.407
- J.T. Fischedick, A. Hazekamp, T. Erkelens, et al., Phytochemistry 71, 2058–2073 (2010).
- E.B. Russo, Frontiers in Pharmacology 7, 1–19 (2016).
- B. Russo, Psychopharmacology 165, 431–432 (2003).
- E.B. Russo, Br. J. Pharmacology 163, 1344–1364 (2011).
- S. Elzinga, J. Fischedick, R. Podkolinski, et al., Nat. Prod. Chem. Res. 3, 1–9 (2015).
- G. Buchbaue, in Handbook of Essential Oils: Science, Technology and Applications, K.H.C. Baser and G. Buchbauer, Eds. (CRC Press, Boca Raton, Florida, 2010) pp. 235–280.
- J.K. Booth, J.E. Page, and J. Bohlmann, PLOS One https://doi.org/10.1371/journal.pone.0173911 (2017).
- R.E. Schultes, W.M. Klein, T. Plowman, et al., “Cannabis: An Example of Taxonomic Neglect. Botanical Museum Leaflets, Harvard University 23, 337–367 (1974).
- S. Johnson, A. Hilyard, P. Henry, S. Tholson, A. Everett, M. Speck, and C. Orser, “Terpenoid Chemoprofiles Distinguish Drug-type Cannabis sativa L. Cultivars in Nevada,” The Emerald Conference (Poster presentation), San Diego, California, 2018.
- Medreleaf (2018) MR2017002 http://www.inspection.gc.ca/english/plaveg/pbrpov/cropreport/mari/app00010960e.shtml.
- MGC (2018) Blockchained DNA: The Information Chain for Advanced Growers and Regulators, https://cdn2.hubspot.net/hubfs/3402974/Medicinal%20Genomics%20Blockchained%20Cannabis%20DNA.pdf?t=1523386278442&utm_campaign=Validation&utm_source=hs_automation&utm_medium=email&utm_content=57554917&_hsenc=p2ANqtz-_0ukN97Yf_qJtgWnKrkKd8eq7WE5cB7PRwFkfDZqJyNkvtN6HyjpQLrq2EdEYdxA5T8-DybGIGtJiTDz6wlTG8yz0RjgsbQmVxSSscNzkY_pENUgU&_hsmi=57554917
- https://phytofacts.info/.
- www.chaibio.com/openqpcr.
Cindy Orser, PhD, with Digipath Labs in Las Vegas, Nevada. Philippe Henry, PhD, is with VSSL Enterprises in Kelowna, British Columbia, Canada. Direct correspondence to cindy@digipath.com.
How to Cite This Article
C Orser and P Henry, Cannabis Science and Technology 2(2), 38-47 (2019).





















Best of the Week: April 11 – April 17, 2025
April 18th 2025Here, we bring you our top four recent articles covering standards in the cannabis industry, a cannabis for sleep survey, a new research and resource center at the University of Mississippi, and in-person information sessions from Metrc.



